For the first weekend of spring break, I went to HackPrinceton with my friend Jared Lim, a CS major here at Cornell. We wanted to apply our machine learning experience with to build something useful. We learned about IBM Watson’s API at the hackathon which greatly facilitated otherwise complicated tasks such as natural language processing. We teamed up with Jia Wei, another Cornellian, and after throwing around ideas, we went with one of my ideas: predicting stock values in the short run. Using datasets from the past, we could generate predictions of the future using ensemble regression methods. However, to account for day-to-day fluctuations, we would use article headlines from Google News collected by webhose.io and evaluate the relative tone using Watson API’s natural language processing abilities and translational abilities. Then, if company X had some issue, the newsfeed would likely deliver a net negative tone which we could translate to a falling stock price the next day. Given a number of articles and how “negative” or “positive” the emotions associated with the headlines were, we could even be able to train our algorithm to quantify the degree of the fall in price. Hopefully, that’d allow the software to project stock price in real time.
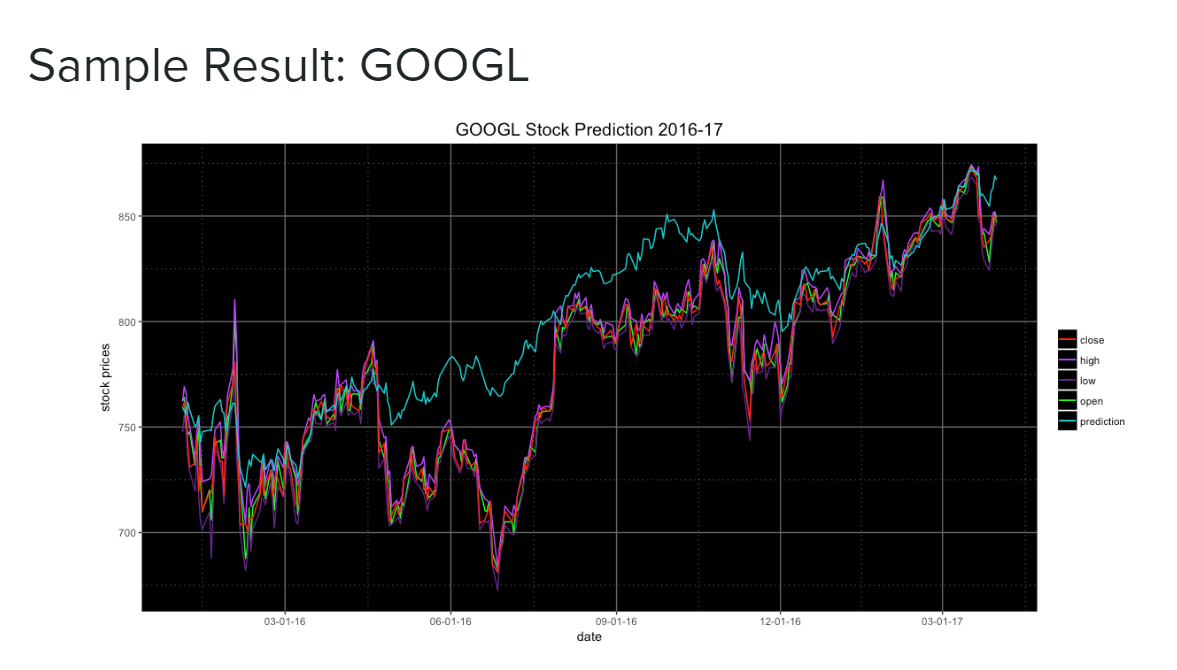
Google stock prediction: notice anomalies due to events like Brexit and the US election
Jia did a front-end interface in the form of a website (HTML/CSS), while Jared worked on the ensemble regression in R, using data I found with a quick Google search from Quandl. I worked on extrapolating information from the news headlines. Using webhose.io, I gathered a large amount of headlines (something around 2000 headlines over the past day) using keywords about the company (such as “Google stock” , “Alphabet Inc.”, etc. if I were finding information for Google). Then, with the emotion tone scores I got from Watson (“Joy”,“Anger”,“Sadness”,“Fear” and “Disgust”), I decided whether the tone was positive or negative and assigned it a relative tone. However, the problem with this was that the process of downloading mass amounts of data and running it through Watson took more time than anticipated, and we weren’t able to add it to the final product, even though my code was finished. And through it all, as it turns out, Watson is very much still an imperfect machine: its tone classification was correct about 2⁄3 of the time, at best.
I had a great time at my first hackathon. In the future, I’d like to take better advantage of the hardware available at these events, and maybe be more creative in what I make: many of the projects were really innovative even if they didn’t have a direct practical application. As I develop more skills I hope my creative boundaries are expanded.

Pre-sleep deprivation
Here is a link to the official presentation of StockTalk: StockTalk Presentation